Platform Specialist
Background
You have been chosen as the new platform specialist at ACME, you step into a role that will shape the foundation of the company’s next-generation safety initiative. The applications developed by the AI and app development teams need a robust, scalable infrastructure, and it’s your responsibility to make that a reality. With incidents rising on the factory floor, the need for reliable AI inference at the edge has never been more critical.
ACME is pushing to modernize its operations while keeping costs in check. By leveraging edge computing, you can deploy AI models directly onto industrial PCs, reducing the load on cloud services and ensuring rapid, localized responses. This approach not only saves money but also enhances performance, as alarms and detections can happen without latency, directly on the factory floor.
However, this initiative isn’t limited to one or two sites. ACME’s factories span the globe, and managing systems at such scale requires careful planning. The solution must be easy to deploy and maintain, even by on site personnel with limited IT expertise. You will be using tools to ensure that updates and configurations can be rolled out seamlessly, keeping all edge devices secure and up-to-date.
Collaboration will be key to success. The development team is building applications designed to operate across both RHEL and OpenShift environments, that means that every edge device will run on RHEL, chosen for its reputation as the most secure and reliable operating system available while in the cloud, OpenShift will provide the flexibility and scalability needed to host dashboards and centralized applications. As the platform specialist, it’s up to you to ensure their work integrates smoothly into the larger ecosystem. The alignment between teams will drive innovation and reinforce ACME’s position as a leader in intelligent, safe manufacturing.
Lastly, one additional note. For the AI inference processing at the edge, ACME has selected the NVIDIA Jetson Orin NANO devices, known for their optimal balance of performance and energy efficiency. This choice introduces an important architectural consideration: the platform must support ARM-based systems and GPU-enabled hardware, expanding the scope of your infrastructure to handle both x86 and ARM architectures seamlessly, and to run ML enabled workload more efficiently.
Toolset
To build and manage the platform supporting ACME’s safety solution, the workshop will leverage a set of robust tools designed to ensure scalability, automation and seamless deployment across both edge and cloud environments. These tools include:
| You will find later that each section of this workshop outlines details about our tool selection rationale and explores alternative options you may consider. |
-
Red Hat Enterprise Linux (RHEL): RHEL serves as the operating system for edge devices, providing a secure, stable, and performance-optimized environment to run AI inference models on industrial PCs. Its long-term support and hardened security make it the preferred choice for mission-critical workloads.
-
OpenShift: OpenShift is the Kubernetes-based platform used to host cloud applications such as the dashboard and backend services. Its integrated developer and operational tools simplify the deployment and management of containerized microservices, enabling automated scaling, self-healing, and seamless edge-cloud integration.
-
ArgoCD: ArgoCD implements GitOps workflows to automate the deployment and synchronization of applications across environments. This ensures that infrastructure and application states are always aligned with the latest configurations stored in version control, reducing drift and enabling fast, consistent rollouts.
-
Flight Control: Flight Control (community Open Source project) streamlines the management of edge devices, allowing the platform team to deploy updates, monitor device health, and orchestrate workloads across distributed fleets of Edge Devices.
-
Bootc: Bootc enables the use of bootable container images as the operating system for edge devices, providing atomic updates, rollbacks, and immutable infrastructure principles. This containerized approach simplifies OS management, enhances security through immutability, and ensures consistent, reliable updates across the edge fleet.
Workflow Overview
Find below the workflow that you will follow as Platform Specialist during the workshop (each of those will be a different "module").
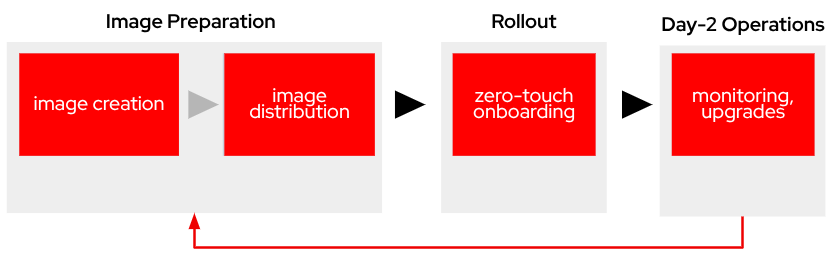
-
Image Baking:
-
Image Creation: Building the base device image with required base OS and configurations
-
Image Distribution: Making the device image available to be used
-
Image Deployment: Automated installation of the Image created and remote access
-
-
Device Onboard:
-
Image Update: Adding management agent to the Image to perform Onboarding onto Flight Control
-
-
Day-2 Operations:
-
Device monitoring: centralized system health monitoring
-
Device updates: deploying application workload and system patches from the centralized console
-
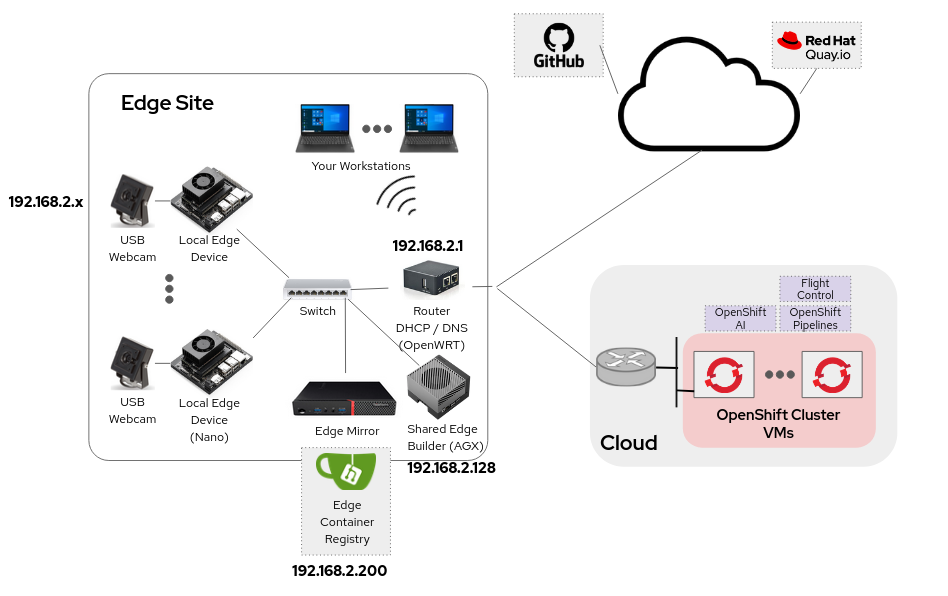
The physical architecture in the lab is the one depicted below (which includes the assigned IP addresses).
|
The lab, with its private network, represents an Edge site with several Local Edge Device (Nvidia Nano) and attached USB cameras distributed inside the factory. The Edge site includes an Edge Mirror server (Lenovo m710q) which is running an Edge Container Registry (Gitea). A Shared Edge Builder (Nvidia AGX) will provide you with the capabilities to build your first system image. Your Workstation will sit on the same network as the Local Edge Device and Edge Container Registry. |
Key feedback loop: Operational insights drive image improvements and updates, ensuring continuous refinement of base images based on real world usage patterns and requirements.